Section:
New Results
Category-level object and scene recognition
SCNet: Learning semantic correspondence
Participants :
Kai Han, Rafael S. Rezende, Bumsub Ham, Kwan-Yee K. Wong, Minsu Cho, Cordelia Schmid, Jean Ponce.
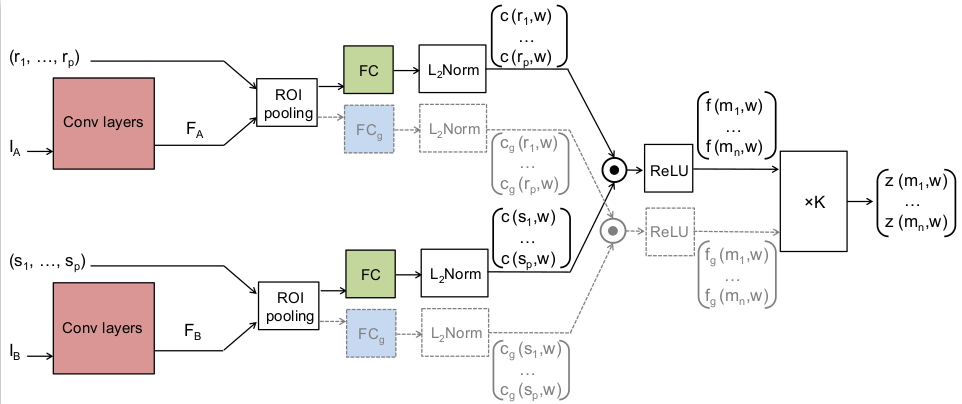
In this work we propose a convolutional neural network architecture, called SCNet, for learning a geometrically plausible model for establishing semantic correspondence between images depicting different instances of the same object or scene category. SCNet uses region proposals as matching primitives, and explicitly incorporates geometric consistency in its loss function. An overview of the architecture can be seen in Figure 5. It is trained on image pairs obtained from the PASCAL VOC 2007 keypoint dataset, and a comparative evaluation on several standard benchmarks demonstrates that the proposed approach substantially outperforms both recent deep learning architectures and previous methods based on hand-crafted features. This work has been published in [13].
Figure
5. The SCNet architectures. Three variants are proposed: SCNet-AG, SCNet-A, and SCNet-AG+. The basic architecture, SCNet-AG, is drawn in solid lines. Colored boxes represent layers with learning parameters and the boxes with the same color share the same parameters. “” denotes the voting layer for geometric scoring. A simplified variant, SCNet-A, learns appearance information only by making the voting layer an identity function. An extended variant, SCNet-AG+, contains an additional stream drawn in dashed lines. SCNet-AG learns a single embedding for both appearance and geometry, whereas SCNet-AG+ learns an additional and separate embedding for geometry.
|
|
Kernel square-loss exemplar machines for image retrieval
Participants :
Rafael S. Rezende, Joaquin Zepeda, Jean Ponce, Francis Bach, Patrick Pérez.
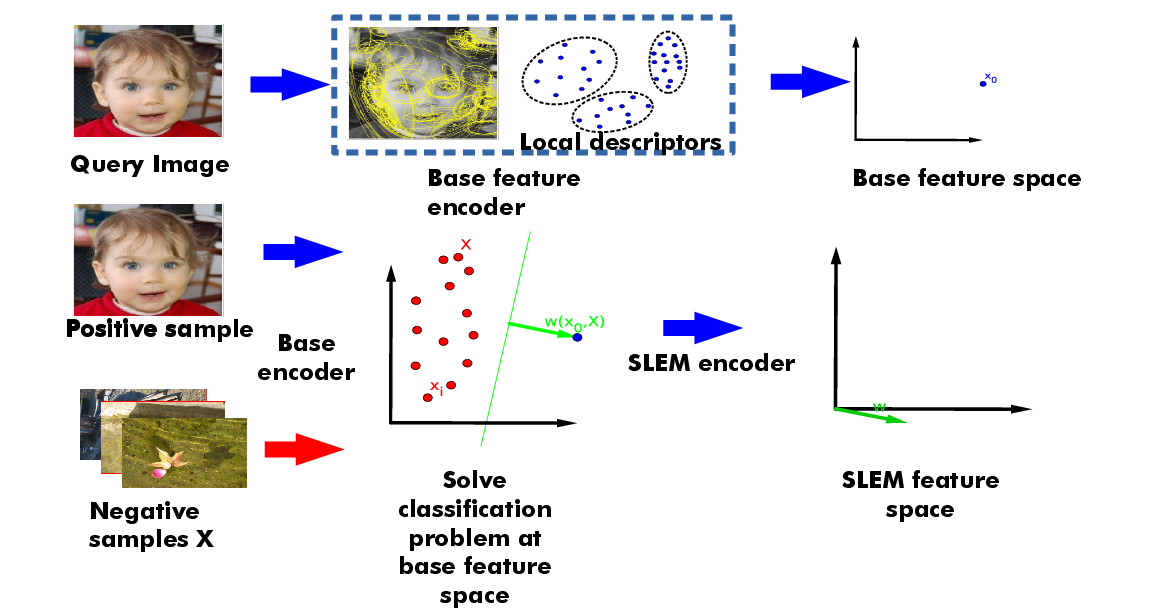
In this work we explore the promise of an exemplar classifier, such as exemplar SVM (ESVM), as a feature encoder for image retrieval and extends this approach in several directions: We first show that replacing the hinge loss by the square loss in the ESVM cost function significantly reduces encoding time with negligible effect on accuracy. We call this model square-loss exemplar machine, or SLEM. An overview of the pipeline can be seen in Figure 6. We then introduce a kernelized SLEM which can be implemented efficiently through low-rank matrix decomposition, and displays improved performance. Both SLEM variants exploit the fact that the negative examples are fixed, so most of the SLEM computational complexity is relegated to an offline process independent of the positive examples. Our experiments establish the performance and computational advantages of our approach using a large array of base features and standard image retrieval datasets. This work has been published in [19].
Figure
6. Pipeline of SLEM. First row encapsulates the construction of a base feature for a query image, which usually consists of extracting, embedding and aggregating local descriptors into a vector, here written as . After repeating the process of base feature calculation a database of sample images and obtaining a matrix of base features, we solve a exemplar classifier by labeling as the lonely positive example (called exemplar) and the columns of as negatives. The solution to this classification problem, which is a function of and , is our SLEM encoding of the query image.
|
|
Weakly-supervised learning of visual relations
Participants :
Julia Peyre, Ivan Laptev, Cordelia Schmid, Josef Sivic.
This paper introduces a novel approach for modeling visual relations
between pairs of objects.
We call relation a triplet of the form where the predicate is typically a
preposition (eg. 'under', 'in front of') or a verb ('hold',
'ride') that links a pair of objects . Learning such relations is challenging as the
objects have different spatial configurations and appearances
depending on the relation in which they occur. Another major
challenge comes from the difficulty to get annotations,
especially at box-level, for all possible triplets, which
makes both learning and evaluation difficult. The
contributions of this paper are threefold. First, we design strong yet flexible visual features that encode the appearance and spatial configuration for pairs of objects. Second, we propose a
weakly-supervised discriminative clustering model to learn
relations from image-level labels only. Third we introduce a
new challenging dataset of unusual relations (UnRel) together
with an exhaustive annotation, that enables accurate
evaluation of visual relation retrieval. We show
experimentally that our model results in state-of-the-art
results on the visual relationship dataset
significantly improving performance on previously
unseen relations (zero-shot learning), and confirm this
observation on our newly introduced UnRel dataset.
This work has been published in [18] and example results are shown in Figure 7.
Figure
7. Examples of top retrieved pairs of boxes in UnRel dataset for unusual queries with our weakly supervised model
|
|
Convolutional neural network architecture for geometric matching
Participants :
Ignacio Rocco, Relja Arandjelović, Josef Sivic.
We address the problem of determining correspondences between two images in agreement with a geometric model such as an affine or thin-plate spline transformation, and estimating its parameters. The contributions of this work are three-fold.
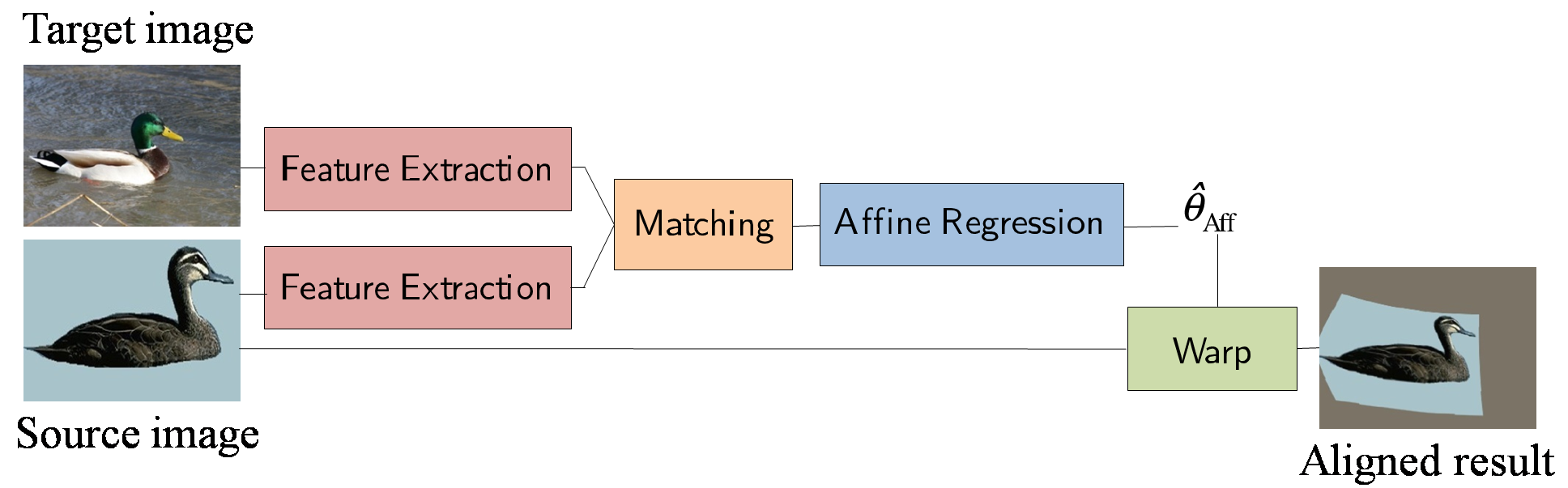
First, we propose a convolutional neural network architecture for geometric matching, illustrated in Figure 8. The architecture is based on three main components that mimic the standard steps of feature extraction, matching and simultaneous inlier detection and model parameter estimation, while being trainable end-to-end.
Second, we demonstrate that the network parameters can be trained from synthetically generated imagery without the need for manual annotation and that our matching layer significantly increases generalization capabilities to never seen before images. Finally, we show that the same model can perform both instance-level and category-level matching giving state-of-the-art results on the challenging Proposal Flow dataset. This work has been published in [20].
Figure
8. Proposed CNN architecture for geometric matching. Source and target images are passed through feature extraction networks which have tied parameters, followed by a matching network which matches the descriptors. The output of the matching network is passed through a regression network which outputs
the parameters of the geometric transformation, which are used to produce the final alignment.
|
|